
what is retrieval augmented generation: A guide to RAG
Think of Retrieval Augmented Generation (RAG) as giving your Large Language Model (LLM) a live, direct line to a specialized library. Instead of just relying on its built-in, pre-trained knowledge, the AI can pull real-time, specific information before it even starts to formulate an answer.
The result? Responses that are far more accurate, relevant, and trustworthy than what a standard LLM can produce on its own.
Bridging the Knowledge Gap in AI
For all their power, LLMs have a major blind spot: their knowledge is stuck in the past. An LLM only knows what it learned from its training data, which can be months or even years old. This creates a "knowledge gap" that causes some very real problems.
The Problem of Static Knowledge
Without access to current information, an LLM is like a brilliant historian trying to comment on today's news using a textbook from 1995. It has incredible reasoning skills and can generate fluent, human-like text, but it has no idea about your company's latest policy, a new product spec, or breaking news from this morning.
This is where the infamous AI "hallucinations" come from. When an LLM doesn't know the answer, it often just… guesses. It confidently makes up facts that sound plausible but are completely wrong. For any business that needs reliable answers, this is a deal-breaker.
How RAG Provides the Solution
RAG fixes this by giving the LLM an "open-book test" for every single question it gets. Instead of just digging into its static memory, the model first retrieves up-to-date information from a trusted knowledge source you provide—like your company's internal wiki, a database of support tickets, or technical manuals.
The process is elegantly simple and happens in two main stages:
- Retrieval: First, the system scans your knowledge base to find the exact snippets of information most relevant to the user's query.
- Generation: Then, the LLM takes this fresh, relevant context and combines it with its own powerful reasoning abilities to craft a complete, fact-based answer.
Essentially, RAG acts as a real-time fact-checker for the LLM. It transforms the AI from a creative but sometimes forgetful storyteller into an expert assistant you can actually depend on.
This simple shift has a massive impact. Studies have shown that adding RAG can slash LLM hallucinations by up to 20%. By grounding every response in real, verifiable data, RAG makes the entire AI system more capable and trustworthy. For a deeper dive into how RAG improves AI reliability, edureka.co offers some great insights.
To make the difference crystal clear, let's break down how a standard LLM stacks up against one with RAG capabilities.
Standard LLM vs RAG-Powered LLM at a Glance
This table offers a quick comparison, highlighting the fundamental differences between a standard LLM and one enhanced with Retrieval Augmented Generation.
| Attribute | Standard LLM | RAG-Powered LLM |
|---|---|---|
| Knowledge Source | Internal, static training data only. | Internal training data plus an external, dynamic knowledge base. |
| Data Freshness | Outdated; frozen at the time of training. | Real-time; can access the most current information. |
| Response Accuracy | Prone to "hallucinations" and factual errors. | Significantly more accurate and factually grounded. |
| Source Citation | Cannot cite sources for its information. | Can provide citations and links back to the source documents. |
| Contextual Awareness | Limited to general knowledge. | Highly aware of specific, domain-relevant context. |
As you can see, RAG isn't just a minor tweak—it fundamentally changes what an LLM can do, turning it from a generalist into a specialist.
How the RAG Architecture Actually Works
So, how does RAG really pull this off? Let's break down its architecture. The easiest way to think about it is as a two-part system: you have a super-fast research assistant (the Retriever) and a skilled communicator (the Generator). These two work in tandem to give you answers that are not only smart but also factually correct.
This teamwork is what makes RAG so different from a standard LLM, which is often stuck with whatever it was taught during its last training run. That data can be months or even years old. The image below paints a clear picture of an LLM flying solo versus one that has RAG as its co-pilot.
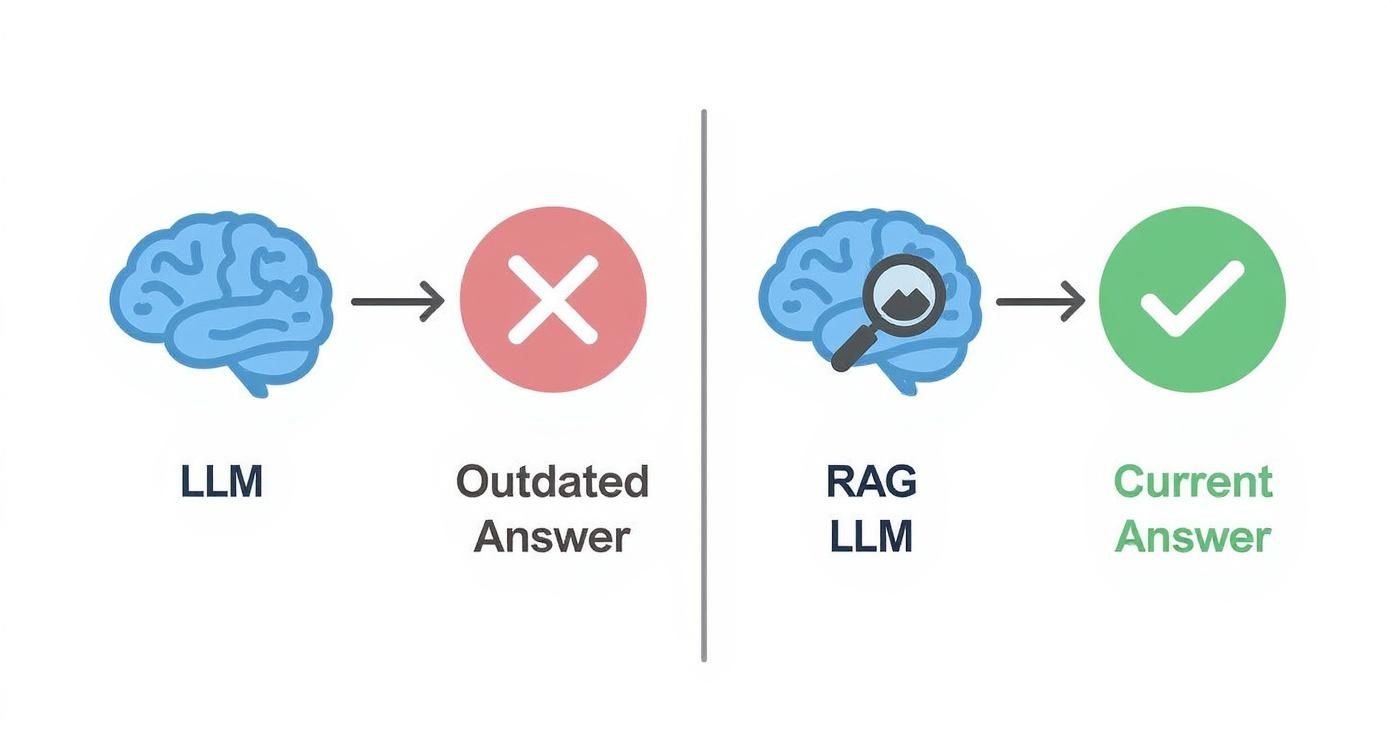
As you can see, RAG essentially adds a real-time fact-checking step into the process. It forces the LLM to ground its response in fresh, verifiable information instead of just its static internal memory.
Step 1: The Retrieval Phase
Everything kicks off the moment you ask a question. This first phase is all about finding the most relevant information to answer that question, and this is where the "research assistant" shines.
First, your question gets converted into a machine-readable format called a vector embedding. Don't let the term intimidate you; it's just a numerical representation that captures the meaning and intent of your query, not just the specific words you used.
This query vector is then used to search a specialized database, which we call a knowledge base. This is where your company's private data lives—internal documents, support tickets, product manuals, you name it. Everything in this knowledge base has also been pre-converted into vector embeddings. The system then searches for the chunks of text from the knowledge base whose vector meaning is closest to your question's vector.
This is really the core magic of RAG. It's not just matching keywords; it's matching concepts. This is why it can find surprisingly relevant answers even if your question is a bit vague or uses different terminology than the source documents.
The system grabs the top most relevant snippets of text and gets them ready for the next step. Now, the AI has a hand-picked, curated set of facts to work with.
Step 2: The Generation Phase
With the right documents in hand, we move on to the second part of the process. This is where the "communicator"—the Large Language Model (LLM)—steps up to the plate.
The bits of text pulled from your knowledge base are bundled together with your original question. This creates a new, much more detailed prompt that gives the LLM all the context it needs. This augmented prompt is then sent to the LLM. For example, platforms like MxChat have integrations that show you just how Perplexity AI uses this method to tap into current information for its answers.
Finally, the LLM takes this rich context and crafts a natural, human-like response. Because it's not just pulling from its own generic training data, the answer you get is fundamentally better.
- Factually Grounded: The LLM is forced to base its answer on the specific information it was just given from your knowledge base.
- Highly Relevant: It directly addresses your question using the precise context it received, not generalized knowledge.
- Trustworthy: Since the information comes from a source you control and trust, the odds of the AI "hallucinating" or making things up plummet.
This two-step process effectively turns a generalist LLM into a subject-matter expert on your specific data, ready to deliver precise, reliable, and context-aware answers every single time.
The Real-World Wins of Using RAG for Your AI
Let's get past the technical diagrams for a moment. The reason RAG is generating so much buzz is because of what it actually does for your AI. Putting RAG to work transforms your AI from a smart-but-outdated generalist into a specialized expert that's grounded in today's facts.
This isn't just a minor upgrade. It delivers four key advantages that directly tackle the biggest headaches associated with standard Large Language Models, making your AI genuinely ready for serious business.
Dramatically Reduce Hallucinations
Here's the biggest win: a huge jump in factual accuracy. We've all seen standard LLMs "hallucinate"—when they don't know something, they just make up a confident-sounding answer. RAG puts a stop to that by forcing the AI to build its response from real, retrieved data instead of just its old training memory.
By grounding the model in external knowledge, you can see a 30% increase in factual accuracy compared to a lonely LLM. As the Institute of Electrical and Electronics Engineers Computer Society points out, this connection to real data makes for an AI you can actually depend on.
Access Up-to-the-Minute Information
A standard LLM is basically a snapshot in time; its knowledge is stuck on the day its training ended. RAG completely breaks down that wall by hooking the model up to live, dynamic information.
Suddenly, your AI can answer questions about things happening right now.
- Recent Events: It can talk about product features that launched this morning.
- Dynamic Data: It can give you the current shipping status of a customer's order.
- Evolving Information: It can reference the newest company policies or the latest market data.
This ability to tap into real-time information makes the AI immediately useful for day-to-day work, ensuring your users get answers that are current, not stale.
Build Trust Through Transparency
People won't use an AI they don't trust. It's that simple. RAG offers a straightforward way to earn that trust by showing its work. Since the system pulls information from specific documents, it can point you right to the source.
When a user asks a question, a RAG system can deliver the answer and a link to the exact document or paragraph it came from. This lets people check the facts for themselves, which builds incredible confidence in what the AI says.
This kind of transparency is a must-have in situations where getting it right is non-negotiable, like in customer support or internal knowledge bases. For instance, a purpose-built document chatbot built with RAG can answer a tricky question about a technical manual and show the user the precise page number where it found the information.
Achieve More Cost-Effective Updates
Trying to keep a massive LLM up-to-date by retraining it is a nightmare. It's slow, computationally intensive, and costs a fortune. RAG gives you a much smarter, leaner way to stay current.
Instead of retraining the whole model, you just update your external knowledge documents. That's it. It’s a faster and dramatically cheaper process that can happen continuously without any model downtime. This makes RAG a truly sustainable way to keep your AI in the loop.
Real-World Examples of RAG in Action
https://www.youtube.com/embed/-yyONUB5b88
Understanding the theory behind Retrieval-Augmented Generation is one thing, but seeing it solve real problems is where you really see the magic happen. RAG isn't just an academic concept; it's a practical tool that companies are using right now to make their AI systems more reliable and genuinely helpful. By hooking Large Language Models up to live, hand-picked data, businesses are building some seriously smart and accurate applications.
These examples show how RAG helps AI graduate from being a fun novelty to a dependable business tool. The applications are popping up everywhere, from customer service desks to internal company operations, proving just how flexible this technology is.
Smarter Customer Support Chatbots
One of the most obvious wins for RAG is in the world of customer support. We've all dealt with a standard chatbot that just follows a script or pulls from a static, often outdated, knowledge base. They tend to fall apart the moment you ask about a new product or a recent policy change.
RAG completely flips the script. Let’s think about a support bot for an online store.
- Before RAG: A customer asks, "What's your return policy for items from the new Summer Collection?" The bot, trained months ago, spits out a generic, outdated return policy. The result? A confused and frustrated customer.
- With RAG: The same question kicks the system into gear. It instantly finds the latest return policy document that specifically mentions the "Summer Collection." The LLM then uses this fresh, accurate information to give a perfect answer, maybe even pointing to the exact clause in the policy.
This means customers get the right information every single time, which cuts down the work for human agents and keeps people happy. As a business grows, a knowledge base chatbot can enhance your WordPress site, serving up instant, reliable answers pulled straight from your own content.
By grounding every answer in up-to-date documentation, RAG turns a support bot from a potential headache into a trusted resource. It's a shift that doesn't just make things more efficient—it builds real trust with your users.
Instant Answers for Internal Teams
The power of RAG isn't just for customers. Think about what happens inside a company. Employees are constantly hunting for information, whether it’s HR policies, IT troubleshooting guides, or complex technical manuals. Digging through a messy shared drive to find the right document is a massive waste of time.
An internal RAG-powered bot is like having an expert colleague who has read and memorized every single company document. An employee can just ask a simple question like, "What are the rules for expensing a business trip to the London office?"
Instead of a frantic search, the system scans all the relevant HR and finance documents in a flash. It pulls the specific sections on international travel and spending limits, then pieces together a clear, direct answer. This gets rid of the guesswork and makes sure everyone is following the right procedures, which is a huge boost for productivity and compliance. In a fast-moving company where getting it right matters, that kind of instant access to verified information is a game-changer.
So, How Do You Actually Build a RAG System?
Okay, we've covered the "what" and the "why" of Retrieval-Augmented Generation. Now comes the interesting part: actually putting one together. Moving from theory to a working system involves a few key decisions. The tech behind it is pretty deep, but the core building blocks are surprisingly straightforward. Getting these right from the start is the secret to building an AI that gives you accurate, reliable answers.
Before you even think about code, you need to obsess over your knowledge base. This is the "brain" of your R.A.G. system, the single source of truth it will draw from. If your source material is a mess, your AI's answers will be, too. It’s that simple.
Step 1: Get Your Knowledge Base in Order
First thing's first: gather and clean your data. This isn’t just a matter of dumping a bunch of files into a folder. You need to make sure the information is correct, current, and doesn't contradict itself. An AI grounded in outdated or conflicting information will just confidently give you outdated, conflicting answers.
A huge part of this prep work is something called chunking. You don't feed whole documents into the system at once. Instead, you break them down into smaller, bite-sized, logical pieces—or "chunks."
Think of it like this: instead of telling someone to find an answer "somewhere in this 500-page book," you're giving them a detailed index that points them to the exact paragraph they need. Good chunking is probably the single biggest lever you can pull to improve retrieval accuracy.
This way, when the retriever finds a match, it serves up a focused, highly relevant snippet of text for the LLM to work with, not a giant document where the real answer is buried on page 37.
Step 2: Pick the Right Models for the Job
A RAG system is a team effort between two different kinds of AI models. Choosing the right partners for this team is critical. You need a retriever and a generator that play well together.
- The Retriever (Embedding Model): This model's entire job is to turn your text and the user's questions into numbers (vectors). The better your embedding model is at capturing the real meaning of the words, the more accurate its search results will be.
- The Generator (Large Language Model): This is the LLM that takes the information the retriever finds and crafts it into a natural, human-like answer. The model you choose here dictates the personality, tone, and quality of the final response.
Different models are good at different things. Some are built for pure speed, which is great for customer service bots. Others are designed for deep, nuanced understanding, perfect for a technical research tool. Knowing how these models work together is fundamental to building a great vector embedding chatbot for your WordPress site with MxChat that truly gets what your users are asking.
Step 3: Fine-Tune the Retrieval Process
Finally, you have to think about how the system pulls that information. It’s not just about finding relevant chunks; it's about finding the most relevant chunks and doing it fast.
A common technique is to set a "top-k" parameter, which just means telling the system how many chunks to grab. If you grab too few (k=1), you might miss some key context. If you grab too many (k=10), you might overwhelm the LLM with noise.
For even better results, many advanced systems add a reranking step. The retriever does a quick, broad search to find a bunch of potentially good documents. Then, a second, smarter model looks at that smaller list and reorders it to put the absolute best matches right at the top. This two-pass approach seriously refines the search results before the generator ever sees them, leading to much higher quality and more precise answers.
Frequently Asked Questions About RAG
When you first start digging into Retrieval Augmented Generation, a few key questions always pop up. It’s a powerful concept—connecting a static Large Language Model to a live, dynamic source of information—but it helps to understand where it fits in and how it differs from other AI methods. Let's tackle some of the most common questions to give you a clearer view.
Getting these answers straight shows why RAG is more than just another AI buzzword. It’s a practical tool for building AI systems that are genuinely reliable and anchored in facts.
What’s the Real Difference Between RAG and Fine-Tuning?
The biggest distinction between RAG and fine-tuning boils down to how an LLM gets and uses new information. Imagine you have an expert on your team. Do you give them a library to consult for answers, or do you send them back to college for a new degree?
- Fine-tuning is like sending them back to college. It permanently alters the LLM’s internal knowledge by retraining it on a specialized dataset. This is great for teaching the model a specific personality, tone, or style. The downside? It’s an expensive and time-consuming process.
- RAG is like giving your expert a library and an open-book test for every question. It doesn't change the core model at all. Instead, it pulls relevant, up-to-the-minute information from an external source to answer each specific query. This makes it perfect for information that changes all the time, like product specs or internal support docs.
Think of it this way: RAG provides knowledge, while fine-tuning teaches a skill. If you need dynamic, fact-based answers, RAG is your tool. If you need to fundamentally change the model's behavior, that's where fine-tuning comes in.
Can RAG Handle Any Kind of Data?
One of the best things about RAG is its flexibility. It can work with pretty much any kind of unstructured or semi-structured text data you can throw at it. The file format itself isn't what matters—it's the quality of the information inside.
You can point a RAG system at all sorts of sources, such as:
- PDFs and Microsoft Word documents
- Web pages and blog articles
- Content from knowledge bases like Notion or Confluence
- Simple text files and chat transcripts
The system takes all this text and turns it into a searchable index of vector embeddings. This means as long as the information can be read and understood, RAG can use it to ground the LLM's responses in reality. Just remember, the cleaner and better-organized your source data is, the more accurate your RAG-powered AI will be.
How Hard Is It to Actually Implement RAG?
While building a RAG pipeline completely from scratch is a serious undertaking that requires deep expertise, the good news is that you don't have to anymore. Getting started is more accessible than ever, and you definitely don’t need an entire team of AI researchers to do it.
The development of frameworks like LangChain and LlamaIndex has been a game-changer. These tools offer ready-made components that do a lot of the heavy lifting for you, from splitting up your data into manageable chunks to retrieving the right information. This has drastically lowered the barrier to entry, allowing more businesses to build powerful RAG applications without needing to become experts in the nitty-gritty details.
Understanding why RAG outperforms a basic keyword lookup helps explain where the retrieval step pulls its weight. We unpack the difference between lexical matching and embedding-based retrieval in our guide to semantic search vs keyword search — the same machinery that powers the retrieval half of any production RAG stack.
Ready to deploy an intelligent AI assistant grounded in your own data? MxChat makes it easy to build powerful, no-code chatbots for your WordPress site using Retrieval Augmented Generation. Discover how MxChat can transform your customer support and lead generation today.





